Hi everyone,
For those who aren't aware, The Forge has suffered multiple major outages during the last week. Nearly every day, we've had some sort of disruption, and sometimes the entire website was down for long periods of time.
Before we delve into the details of what occurred during this dreadful month of February 2023, I'd like to start by offering my sincere and deepest apologies to anyone whose games had been affected by the disruption of service that The Forge encountered in the last week.
We know how hard it can be to schedule a game with friends, and that the game might be the highlight of your week. Some of you may also be professional GMs depending on it as a source of income. We are gamers just like you, and we know that it is never pleasant to be plagued by technical difficulties, pulling us down from our imagination back to the reality of this world.
We will back our apologies with facts and with action. In our continued efforts of transparency, we will be explaining exactly what happened, why it happened and how it happened, as well as how we've solved the problem and what we're doing to ensure it doesn't happen again. This is what this post-mortem is for.
We will also offer a credit to all users affected by the service disruption, equal to 110% of their monthly subscription cost. We include information on how to request this credit below.
Finally, I'd like to thank our players, and our community for their patience, and understanding as we struggled through this difficult time. The outpouring of love from our users, both on Discord as well as Twitter, far outweighed the (justified) frustration we've seen from other members. We're truly humbled and grateful to be part of such an understanding and beautiful community.
The summary
For years now, we've had various issues with our service provider, DigitalOcean (DO) providing subpar services and causing various stability issues. While DO is a very popular and well known service provider, they simply don't seem to be of a level of quality and reliability that we'd want for our business.
We promised our customers almost two years ago that we'd work on moving to a new—and more stable—service provider so we could provide our customers with the performance and stability they deserve. That server migration took a lot of effort and a lot of time. We first deployed our Oceania servers with OVH as a testbed for a new, and more reliable infrastructure. Once we were satisfied with the service offered and our new design, we migrated our EU servers to the new datacenter. That went well, and we've received a lot of useful feedback from our European users, who have found it more reliable and faster than ever. The migration didn't go perfectly though, and we've found a few areas that we needed to improve upon before moving our biggest region (North America) to OVH as well.
That was nearly a year ago, and we've solved many of the challenges we had encountered and we were ready to finally move the rest of our users to OVH as well, especially with the repeated issues we've seen with DigitalOcean in the last few months.
Since January, we've been working full time on the setup of the new servers, and slowly migrating users' data from DigitalOcean to OVH. For some reason, DigitalOcean thought that the amount of data transferred was too much (even though we took every precaution to prevent that) and "in order to protect our other customers" they decided to completely unplug our servers from the internet. They considered it as if it was a DDoS attack and they were protecting the servers from the attack by literally just isolating it completely for 3 hours.
To be clear, it is our belief that DigitalOcean's protection system was incorrectly triggering and had completely erroneous statistics (reporting to us as much as a thousand times more traffic than what was actually being used). It is also our belief that DigitalOcean's decision to unplug a computer from the internet to protect it from a Denial of Service attack is the most absurd and senseless thing we've heard in the last decade.
Needless to say, this had a very large impact on our services and triggered a chain reaction of events that took a tremendous effort to recover from. It was also unfortunate that DigitalOcean decided to randomly isolate our servers multiple times a day, every day for nearly a week, and we were powerless to stop any of it.
In the end, our saving grace was that we had already finished migrating the user's data to our new OVH servers. Though the new servers were not ready to be used yet, (we still needed about two weeks of work before we even started testing the new infrastructure), we were forced to act quickly and initiate an immediate emergency move of our infrastructure to our new service provider. Blessedly, the issues had mostly stopped after we did the move and service was restored, and has been very stable and reliable ever since. Everything wasn't perfect though, as I had rushed through 2 weeks of work in about 3 hours—and with no testing—in order to restore services as quickly as possible, and so we had a few small hiccups in the early days after the migration.
And so, thankfully, since Saturday the 25th, we haven't had any such outages like we've had all week, and our North American region users have had the most reliable and fast performance we've had in years!
More work remains to be done to finish the migration and we'll continue our migration at a more delicate pace now, being careful not to disrupt any active games. One thing users might notice for example is that the "daily backups" available in our Save Points interface, have stopped since February 17th. Don't worry though, we are still taking daily backups of everyone's data, and newer backups will become available for users to restore games from as soon as we finish our server setup.
Claiming a credit
The Forge isn't one of those few mega-corporations spending millions of dollars in various redundancies so that they can promise high uptime and offer SLAs (Service Level Agreement). However, we stand by our work, and we feel that our customers do not deserve to pay for a service that was not meeting either their, or our expectations.
To that end, we're offering credit for our user's February subscriptions, and will credit you a value equal to 110% (up to 128% in some cases) the monthly subscription cost for February (better than AWS's own SLA terms!).
To make things simple, Game Master subscribers will get a 5$ credit, Story Teller subscribers will get a 10$ credit, and finally, a 15$ credit for World Builder subscribers.
If you were affected by the disruption of service that occurred in the last week, then please reach out to us via email to [email protected] and make sure to send the email from the same email address that is associated with your Forge account, so we can find and match your account details.
Let's get technical!
At this point, I'm going to get into the nitty gritty details of what happened exactly and how things got resolved. I'll get very technical, though I will try to keep things simple and concise (fair warning: I'm not very good at that). Due to the extent of issues we've had to tackle, the rest of this post will be very long, so feel free to skip it. Anything worth knowing (the summary of the situation and the credit instructions) was written before this point. The important part being that the issues have been resolved.
What happened and why?
To put it mildly: DigitalOcean messed us up really badly.
While I believe some of the things we did ended up causing DigitalOcean to blackhole our servers, I still firmly believe that we took every precaution to make the transfer happen smoothly and what they did was completely unpredictable and is unquestionably absurd and unacceptable and should never have happened in the first place.
Prelude to the story: I've been working full time on setting up our new servers on OVH for about a month. The idea was that we would create a new region that would be "North America (new servers)" that people can migrate to. One of the lessons learned with our EU migration was that there was a bit of complication with regards to moving user's data from one storage cluster to the next.
For the technical aspect, we use the Ceph distributed storage cluster for our storage solution, and one of its capabilities is the addition/removal of servers and drives and it will automatically sync up the data between servers and handle replication. The idea that I've had to make the migration as smooth as possible was to simply add the new servers to the storage cluster so there is no need to sync data back and forth on a per-user basis, and instead let the Ceph system take care of moving the data from OSDs (Object Storage Daemons) in one datacenter to OSDs in the other. This would allow instant migration of our users to the new datacenter without having to lock any account or wait for users to be logged out of their games to initiate it.
Another important piece of information is that all our datacenters are connected to each other via a WireGuard VPN which uses the UDP protocol to establish communication between two servers. This means that any data going from DigitalOcean NYC3 datacenter to the OVH BHS5 datacenter would go through the VPN server to be encrypted and transferred.
I set up our Ceph cluster on OVH and joined it to the cluster in DO, making sure that everything was going to work, and it did. We then attempted the migration of the data from our development environment to ensure everything was working right, before we attempted it on our production environment. The migration went great, though we didn't want to saturate the connection or overload our bandwidth or servers or anything, so we limited the "recovery throughput" (which is how data gets transferred) to a bit under 10MiB/s, we made sure that the bandwidth usage of the host was under 100Mbps for the most part, and we also contacted OVH to ensure that their DDoS mitigation would not trigger for that amount of traffic, which they've helped us with and adjusted threshold accordingly to make sure it didn't cause any issues. So we basically had whitelisted our VPN servers so that they never get mitigated by OVH's DDoS protection and we don't lose connection between our datacenters, as that was important.
We did not contact DigitalOcean to ask for the same thing, as DigitalOcean does not actually have a DDoS mitigation system. So, as far as we knew, we took every precaution to ensure that the migration went smoothly.
We started progressively adding OSDs from OVH to the Ceph cluster and letting data be rebalanced between our datacenters. Since we were in no hurry and still had lots of things to do, the migration of the data was working at about 7MiB/s and took about a week to complete. The way we've set it up is that we created a custom Ceph CRUSH (Controlled Replication Under Scalable Hashing) rule so that the data would be replicated with a datacenter failure domain, ensuring that data will always be available simultaneously on disks in DigitalOcean and in OVH, ensuring the lowest latency and network usage and ensuring that if one datacenter became unavailable, they would both still have a full copy of all the data. This ensured that all reads were happening locally and any data writes would get replicated between the two datacenters.
After about a week of transferring data and a couple of days with all data synchronized between the two datacenter and running without incident, we suddenly received an email from DigitalOcean notifying us that they "Blackholed" our server due to an "inbound Denial of Service attack". For those of you who were on Discord at the time, you may have seen this screenshot :
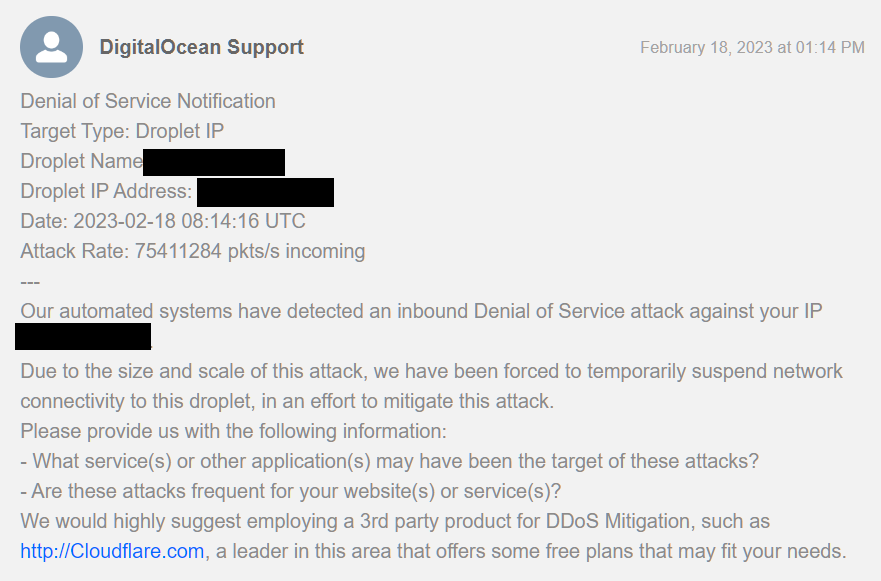
Contrary to what OVH does when a DDoS mitigation is in progress (which just prevents the bad actor from overloading the server), DigitalOcean's concept of DDoS protection is to blackhole the entire server, effectively unplugging it completely from the internet. Since this was our main VPN server, it meant that it didn't just disconnect the new OVH region from the DigitalOcean one (which wouldn't have caused any major disruption), but it disconnected all regions from the DigitalOcean North American one, including our European, Asian and Oceania regions which couldn't communicate with the VPN server either. This also dropped one out of 3 load balancers for the Forge service as a whole, which of course caused its own set of problems. Multiple services had died as they depend on these connections, including, among other things, the North American database servers (we use a 5 node replicaset, with 2 nodes in NA, so there was a new quorum from the remaining 3 regions, which is why the other regions weren't affected by this as much).
I immediately reached out to DigitalOcean to tell them to restore my service, because if the purpose of a Denial of Service is to deny service to a website by overloading it until it can't respond to requests, then... disconnecting the server from the internet would be an even worse solution as a DDoS protection. Their answer was that they don't have DDoS Protection and that this is to protect other customers of DigitalOcean basically, and the blackhole will last 3 hours.
Here's where I have an issue though. They reported 75M packets per second, and they said we were using 108Gbps of traffic, and looking at the server logs, there was no spike in requests to our load balancer (and we're already behind CloudFlare which didn't show any attack in progress), no spike in CPU usage or load, and as far as I know, the physical hardware that the VM is on doesn't even have a network card capable of 108Gbps (my understanding is that they use 40Gbps cards). I could also see from the network monitoring graphs that the server never received any traffic above 200Mbps.
Cutting the story short, that server getting blackholed had devastating consequences on our infrastructure as we had a huge chain reaction of events and services dropping one after the other.
I immediately attempted to set up a different server as our new VPN, but failed because the blackholed server was also our bastion. SSH tunnels, automations, access to monitoring systems, dashboards and databases were no longer available.
None of that was unmanageable of course, since I did have other servers I could SSH to as a fallback (never have a single entry point in case of failure!), and I still had access to all our playbooks and configs, but there was lost time in changing my existing setup to use a different fallback server as SSH bastion and then copying all the files I needed to the new server. Thankfully, the blackholed servers was still accessible via its VPC (private network) so I could also copy the WireGuard configuration, including its private keys so that the other VPN servers would recognize the new server as the new endpoint and update their connections automatically. This saved me some time in that I didn't need to reconfigure the VPN servers in every datacenter (although I did have to do it for our EU VPN because for some reason it was refusing to update its endpoint).
Once I had a new VPN server up and running and my setup reconfigured, it was time to assess the damage. The problem with losing access to the ceph cluster for such a long time was that many servers had simply timed out trying to re-establish connection. This meant that all nodes in our kubernetes cluster had to actually be rebooted because the CSI plugin handling the mounting of the cephfs storage had failed and it was impossible to remount it anymore. On some other servers, processes trying to access files (including the ceph-fuse mounter itself) had frozen to the point of being unkillable even with 'kill -9', forcing more server reboots. Some of the OSDs in the cluster itself had also crashed and refused to boot back up until I manually fixed their issues individually and started them up manually one at a time. The static route operator in our Kubernetes deployment had entered into a crash loop and had stopped managing our IP routes, which meant that it couldn't tell the node to use the new VPN server for intra-datacenter communications. In one of the nodes, the docker daemon itself had completely frozen up and wasn't responding to commands and required a reboot of the node. Some other services, like livekit and other internal tools, use a Persistent Volume Claim which is backed by a Ceph volume, so once Ceph communication was interrupted, those pods were failing their liveness checks and were getting killed, which also led to some invalid state in our Redis StatefulSet which prevented Livekit from booting back up.
There was about 100 things that went wrong, each needing to be handled differently and individually. It took about 3 hours total I believe in order to restore the service to what it was, and things went back to normal.
The next day, the same issue happened again with DigitalOcean blackholing the new VPN server! This indicated to me that there was no actual DDoS but the VPN traffic was what made them blackhole the servers. This was later confirmed as every day, they would target the specific server acting as the VPN. It didn't make sense however as they would say they're receiving 100+Gbps or 16+Gbps, etc... which was a physical impossibility. The OVH server acting as the VPN proxy had a physical limit of 1Gbps upload, and the WireGuard statistics showed an average usage of 80GB per 24 hours period (about 8Mbps), and like I said before, bandwidth monitoring was proving that usage was always under 100Mbps to the server at any given time. So not only did DigitalOcean use a "protection" that was destructive, but they also had an issue in their own statistics, triggering false positives. My guess is that their protection system was lagging and considering an hour's worth of data as if it all came in a single second. Who knows at this point, they haven't been very helpful!
Another interesting bit of information is that this happened at 3:14 AM EST which I found to be weird since that was the bottom end of the peak hour and the servers were most underutilized compared to the rest of the day. The next 3 black hole events also happened around 3AM, which didn't make sense with regards to the amount of traffic and convinced me further that it was a recurring bug in DigitalOcean's detection system (perhaps due to a log rotation on their side, or something like that). I originally thought it might have been due to our daily backups generating too much traffic, but I disabled them temporarily on February 18th, and that didn't change anything.
I was hoping that the initial issue was just a fluke, as we couldn't re-migrate the data back to DigitalOcean at this point since it was already done transferring and that took a week in itself to complete. One thing that I thought might have caused it is the intra-OSD communication (replicating data from one datacenter to the other when writes were occuring) might be too heavy, or that maybe a node in DigitalOcean was doing its read/writes to OVH directly, instead of using the closest OSD to it. Since we were 50% of the way there, I decided to stop the splitting of the data and continue the migration with the replication being entirely local to the OVH database.
When we got blackholed again the next day, the issue was resolved in about 30 minutes, and then 7 minutes when it happened again on February 20th! I've gotten better at recovering the system when DigitalOcean does this. In the meantime, I had taken various measures to avoid any kind of surge in traffic and continued to work on completing the setup of the new servers as quickly as possible so we could be rid of DigitalOcean once and for all.
On February 22nd, another outage occurred which was unfortunately impossible to recover from in the usual way. We didn't get our server blackholed, but I believe the latency between the servers on DigitalOcean and the storage cluster on OVH caused a lot of the data-accessing processes to freeze up, as most servers were waiting on I/O and had a suddenly very high load. When investigating, I found out that pings on the internal network (DigitalOcean VPC) between servers were fluctuating between 60ms and 100ms! Can you imagine a 100ms ping on a local area network (the normal ping is usually around 0.3ms)! Of course, that brought everything to a crawl, and all network and disk I/O were freezing, causing the site to become unresponsive and the ceph mounts to lock up or crash.
With DigitalOcean's local network apparently broken, it was clearly impossible to access anything and nothing worked. Any I/O was lagging and taking forever to complete, and eventually the Ceph cluster died out again, which generated the same sort of chain reaction of failures, even if the VPN wasn't blackholed.
At that point, I knew that it was going to be impossible to recover anything with DigitalOcean, so I rushed to finish the set up of our essential services on OVH, and deployed our infrastructure there, with the configuration to make it think it was still running on DO, which worked. I moved our DNS to the new load balancers on OVH (which had already been set up and in testing) and from that moment on, the site was back to being functional.
While that managed to alleviate the problem, by simply moving away from DigitalOcean, we still got blackholed the next day, even if there wasn't any data being moved (the Ceph cluster and all the deployments were already in OVH at that point).
We've had multiple smaller interruptions in the days that followed, mostly due to configuration mistakes or things that still needed to be done to complete the server setup. As an example, our autoscaler wasn't working properly the first day, which caused failure to launch games at one point. Also, enabling a firewall on a server caused an interruption of a few seconds since it was not configured properly. There was also a misconfiguration in the Oceania kubernetes cluster which prevented some deployments from accessing the database (once the primary was moved to OVH) since that cluster wasn't in the same VLAN. That caused D&D Beyond importing and Save Points functionality to be broken for a day in the Oceania region until I noticed and fixed it. We also had an issue with rate limiting where some images failed to load because the new load balancer was too restrictive in its DDoS protection (that was the feature I was testing on the new servers before the problems occurred).
All of those issues were much smaller in comparison and only lasted a few seconds or a couple of minutes, and were all directly the result of moving most of the infrastructure to OVH in about 3 hours when we really need 2 more weeks to configure things and then test it and clear out all those glitches.
We're not done with the configuration of the new OVH servers and not everything has been migrated off of DigitalOcean (the Livekit servers are still in DO for example, as well as the assets library). But the website, the Foundry servers, and our proxies are all on OVH now, ensuring optimal performance and more importantly, stability.
Now that everything is stable and working, I want us to take our time to finish this migration, because, well, we don't want to make mistakes, or cause further disruptions, and because I need to rest after a very stressful month (and working about 80 hours every week on this)! So if you'll allow me to take a short rest and replenish my spell slots, I'll continue to take care of things so you don't have to worry about further issues.
Moving forward
There is still a lot of things for us to do before we can consider the datacenter migration to be done, and of course, we're very closely monitoring everything, but I'm confident that things are now stable and our monitoring is showing the best performance we've ever had in years.
As for similar issues arising in the future, eliminating any single point of failure is extremely important in order to have a reliable service. Our VPN server being that single point of failure was a known issue, and moving to OVH was the first step to addressing it. Our Oceania and European servers already have multiple VPN servers and use VVRP to ensure it's always up, and our IP routing is based on a floating IP address on the private VLAN. This ensures that if the VPN server goes down, it gets detected within seconds, and a different server takes over with all traffic getting redirected to it automatically. Unfortunately, this is something that we could not achieve on DigitalOcean because of how their network is setup, it prevents us from assigning floating IPs on the VPC, which means that it would not be possible to do it in DigitalOcean (we tried).
I think that the biggest "how can you ensure this doesn't happen anymore" answer would be "stop using DigitalOcean" which is something that is already being worked on and is already the case for most of our infrastructure in North America. We will also be moving our Asian servers to OVH once we are done with the current setup.
As part of our avoidance on single points of failure, we were also already in the process of adding support to our autoscaler service to use multi-datacenter support with fallback options, so that if, for example, OVH has an issue creating new VM instances, then we can use a different provider as a fallback and ensure that we're never stuck with limited resources when a provider's API becomes unavailable. While this work was already started, it wasn't finished and had to be put on pause while the service outages occurred. Continuing that work will allow us to have much higher reliability, so that we never depend on a single service provider or a single server being up at all times.
Thank you for trusting us with your games, and we hope that this helps you better understand what happened and how it was resolved, and helps restore your confidence in us, if any was lost (if not, the credit offer hopefully helps salve that wound).